Aditya Singh
Introduction
This project focuses on leveraging TensorFlow to build and train a neural network for lip reading. The significance lies in promoting accessibility for individuals with hearing impairments, improving human-computer interaction, and contributing to the forefront of technological advancements in artificial intelligence. The integration of deep learning principles showcases the potential for addressing real-world challenges and shaping the future of technology.
Dataset
The dataset used for this project is a portion of the GRID dataset used in the orignal LipNet paper. The GRID corpus consists of 34 subjects, each narrating 1000 sentences. The videos for speaker 21 are missing, and a few others are empty or corrupt, leaving 32746 usable videos.
Import Dependencies
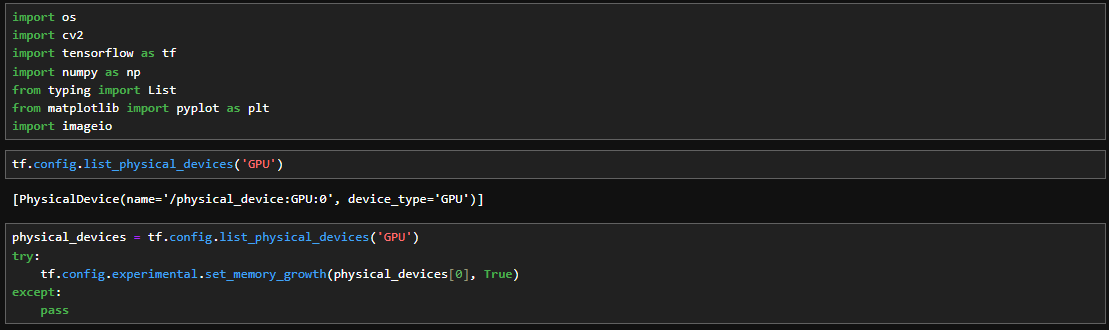
physical_devices = tf.config.list_physical_devices('GPU') : Lists available physical GPU devices.
tf.config.experimental.set_memory_growth(physical_devices[0], True) : Sets GPU memory growth to True for the first GPU device if available. This allows TensorFlow to allocate memory on the GPU as needed, preventing it from allocating the entire GPU memory upfront.
Build Data Loading Functions
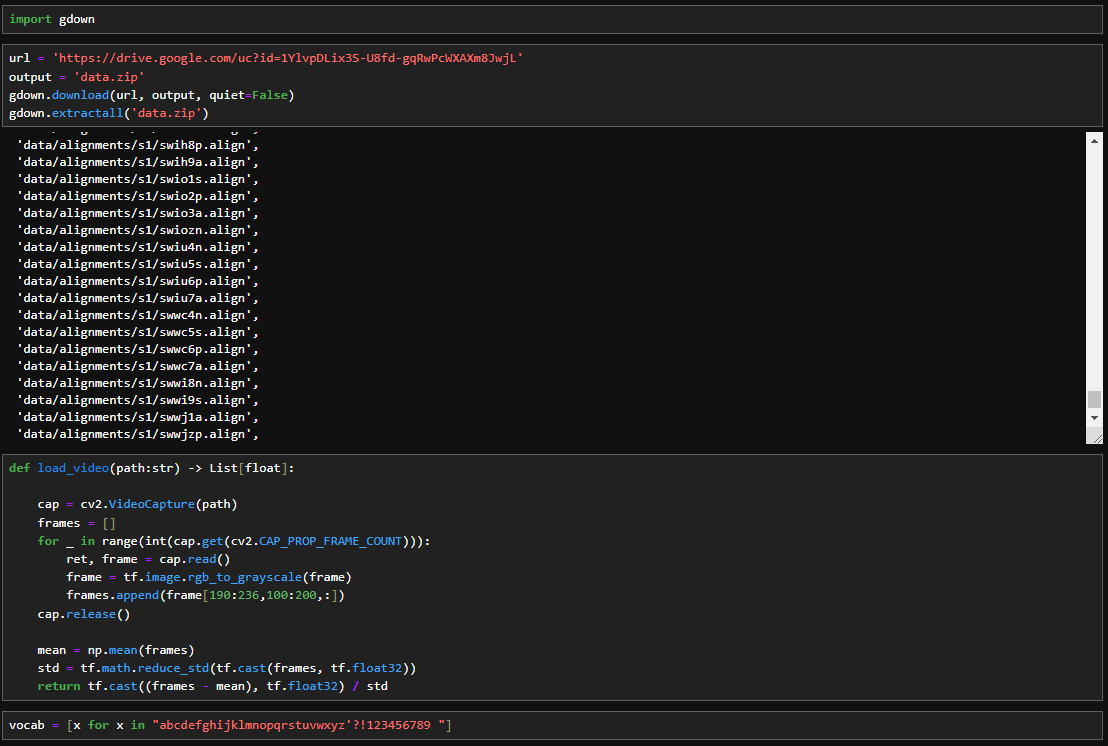
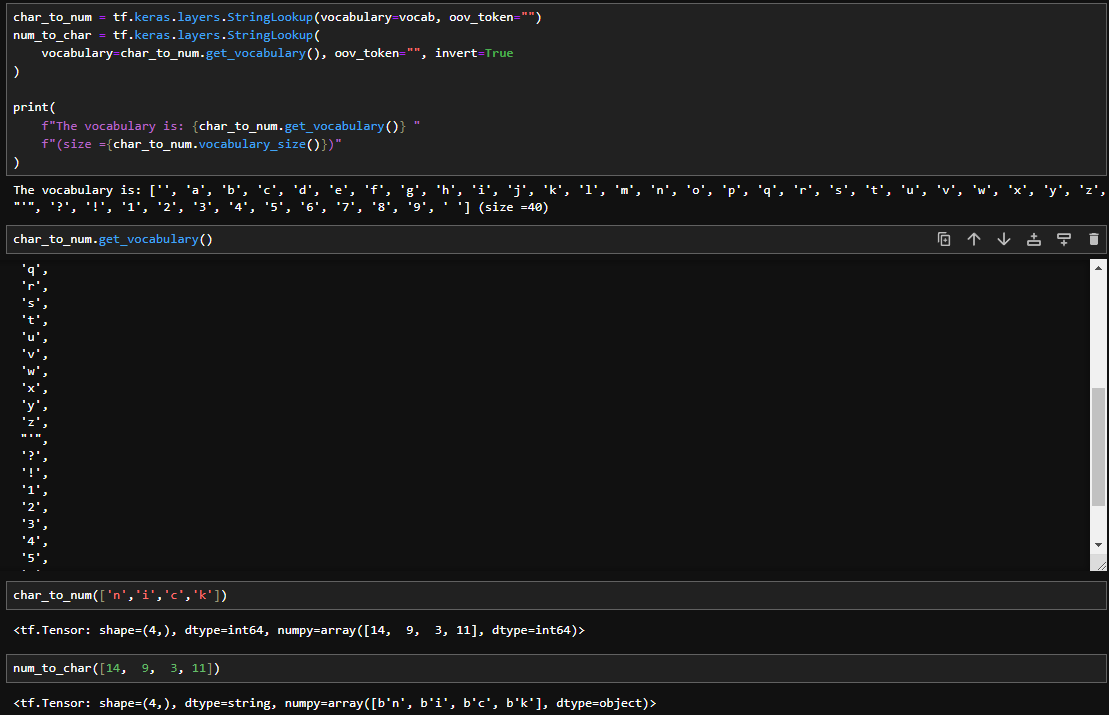
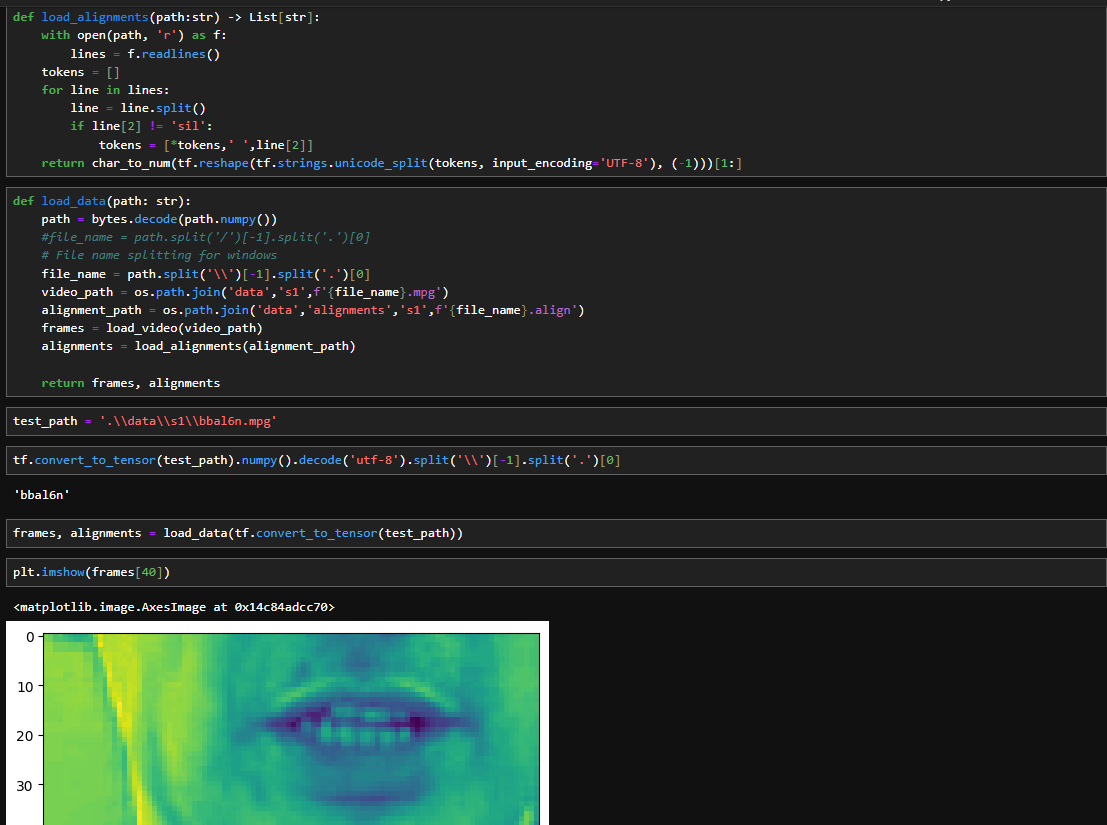
The provided code is a Python script for loading and processing data. It uses the gdown library to download a zip file from Google Drive, extracts its contents, and defines functions for loading video frames and corresponding text alignments. The load_video function reads a video file, converts frames to grayscale, extracts a specific region of interest, and normalizes pixel values. The script defines a vocabulary for characters and maps them to numerical indices.
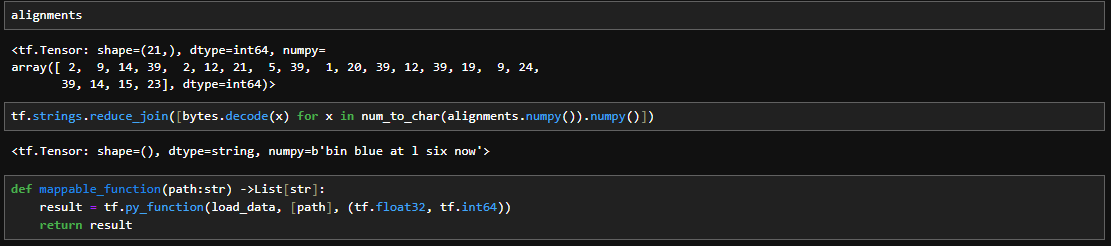
The load_alignments function processes text alignment files, excluding silence tokens. The load_data function combines video frames and text alignments based on the provided file path. Lastly, the mappable_function utilizes TensorFlow's py_function to create a map function for efficient data loading in a TensorFlow dataset pipeline. This code serves as a crucial preprocessing step for training a lip-reading model, handling data extraction, normalization, and alignment processing.
Create Data Pipeline
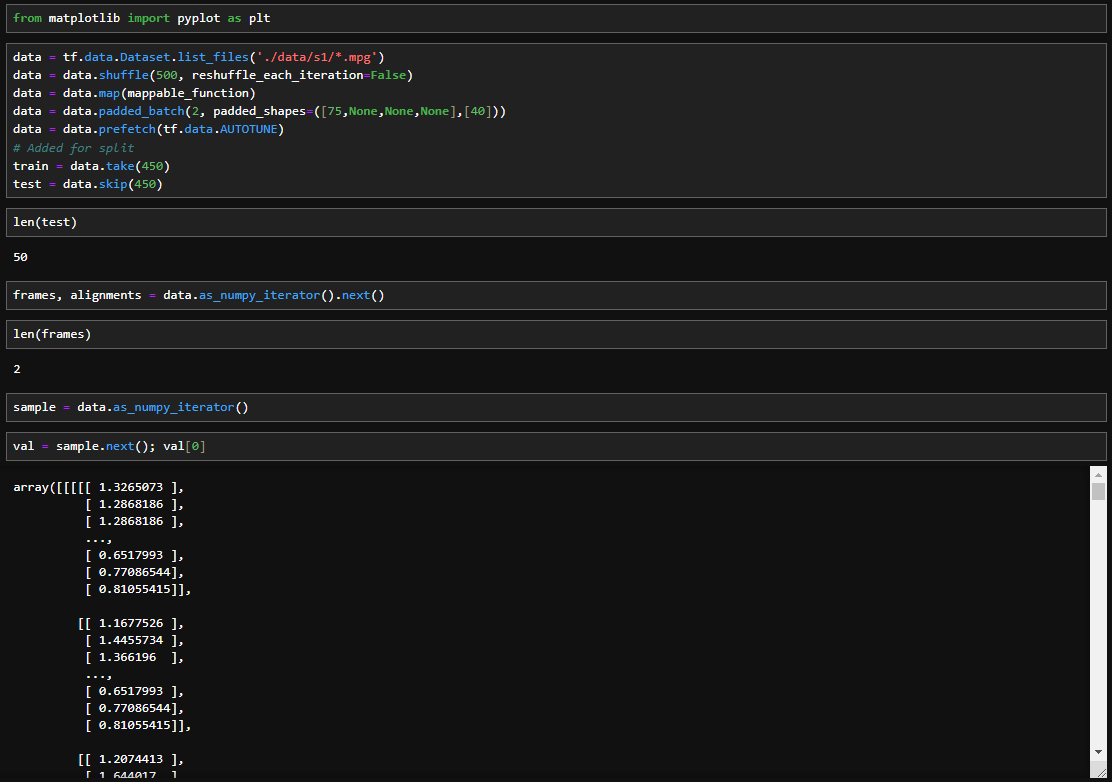
The provided code utilizes TensorFlow's Dataset API to create a pipeline for loading and preprocessing data. It starts by creating a dataset from a list of file paths corresponding to video files in the './data/s1/' directory.
The dataset is then shuffled with a buffer size of 500, ensuring that the order of elements is randomized without reshuffling at each iteration. The mappable_function is applied to each element in the dataset, which loads video frames and text alignments. The dataset is further processed by padding the batches to have a fixed shape of ([75, None, None, None], [40]) and grouped into batches of size 2.
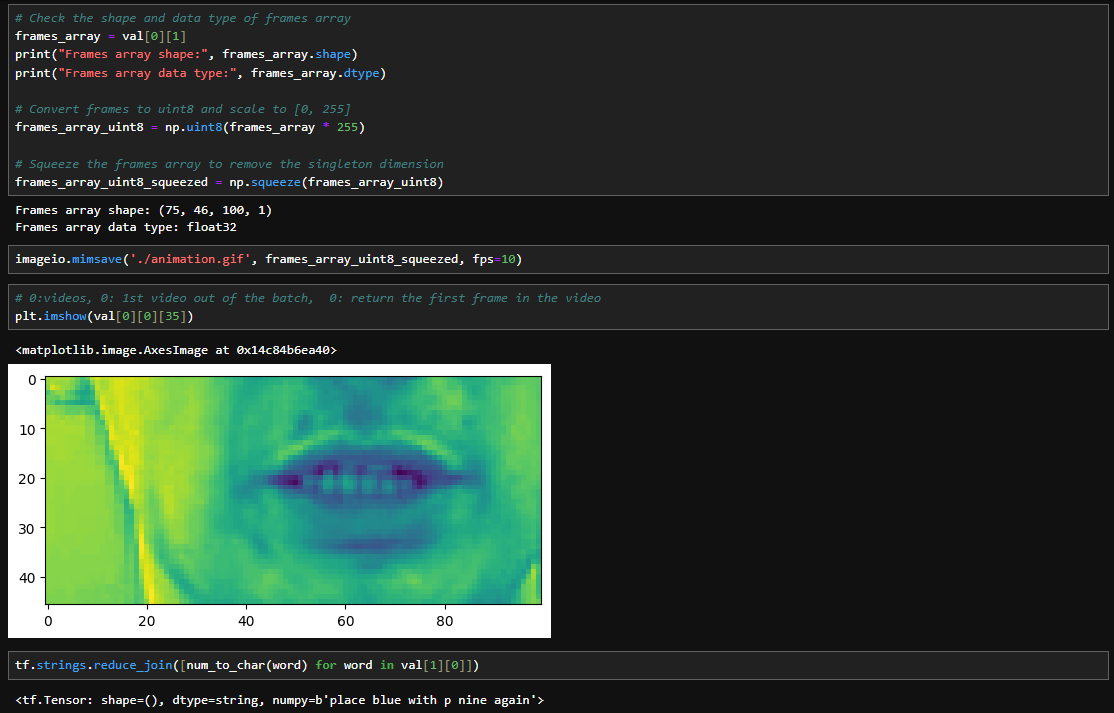
Finally, the dataset is prefetched to optimize performance, and a train-test split is created with 450 samples used for training and the remaining for testing. This code prepares the data pipeline for subsequent training of a lip-reading model, ensuring efficient and organized data input.
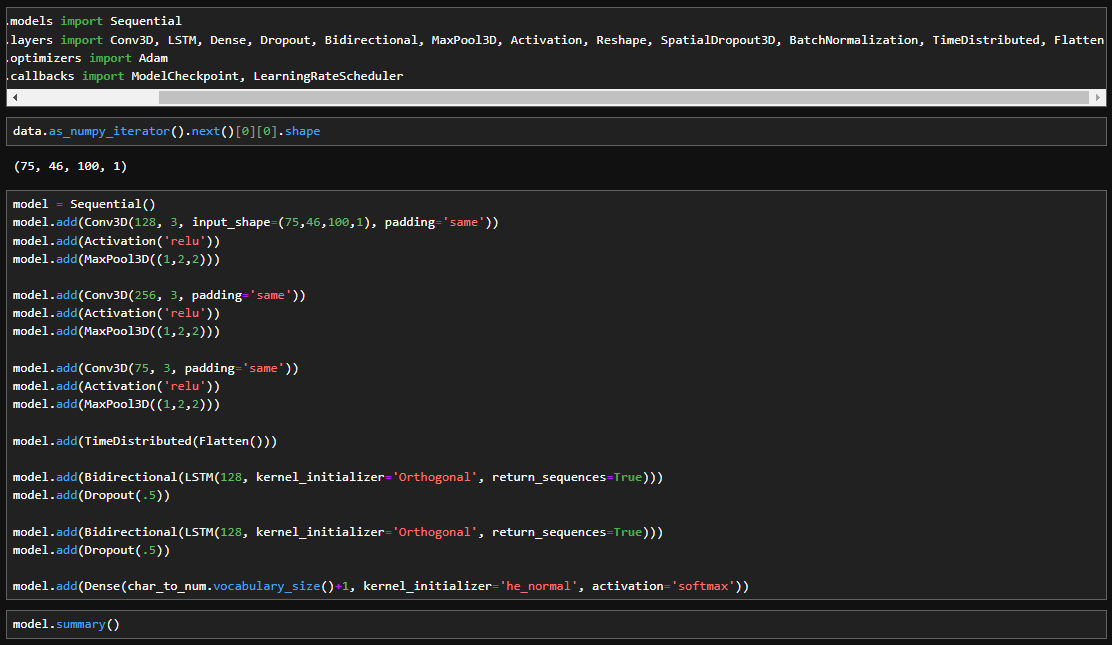
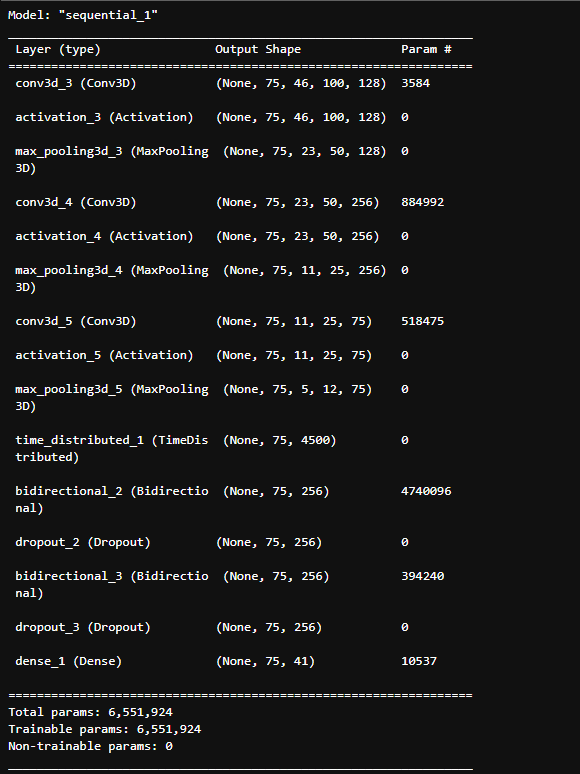
Design the Deep Neural Network
Setup Training Options and Train
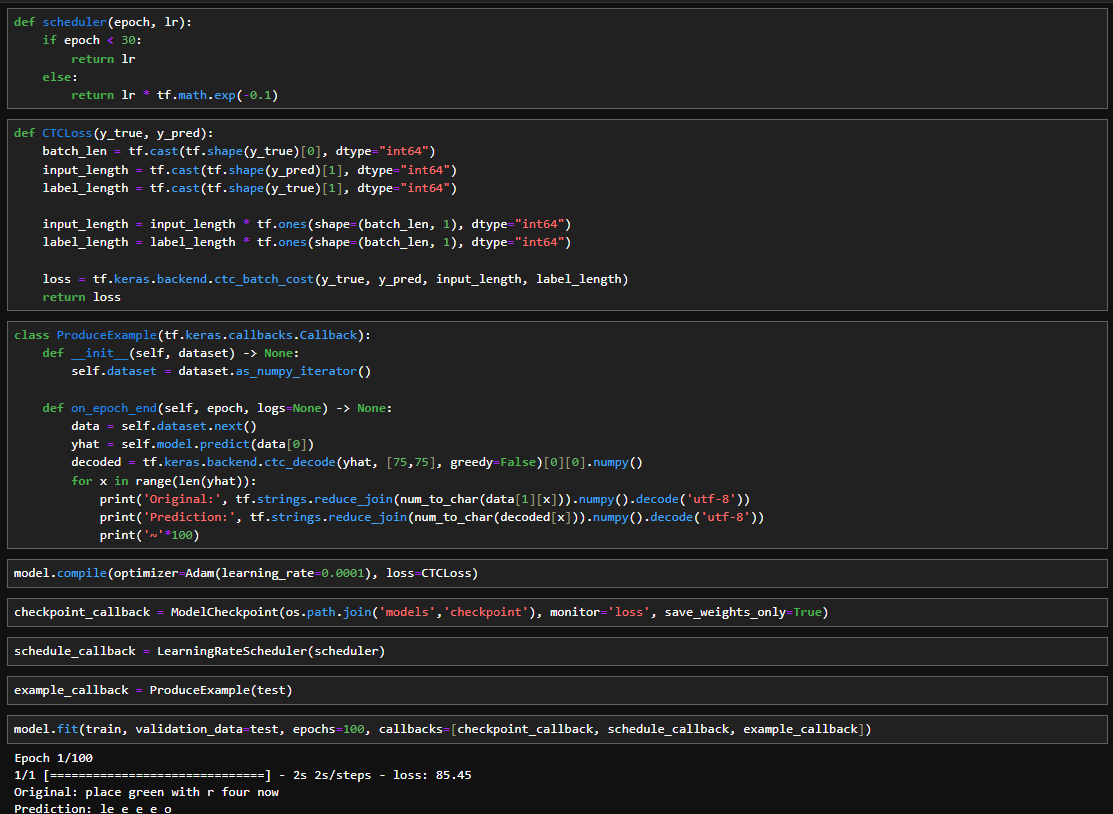
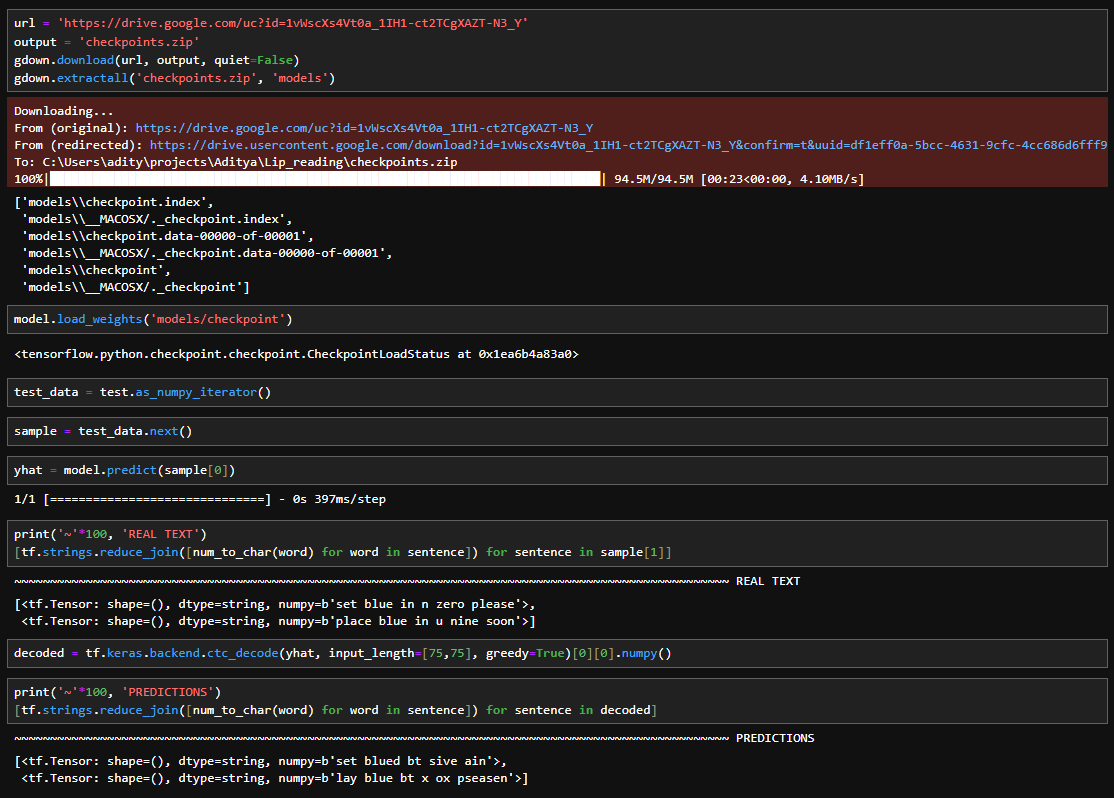
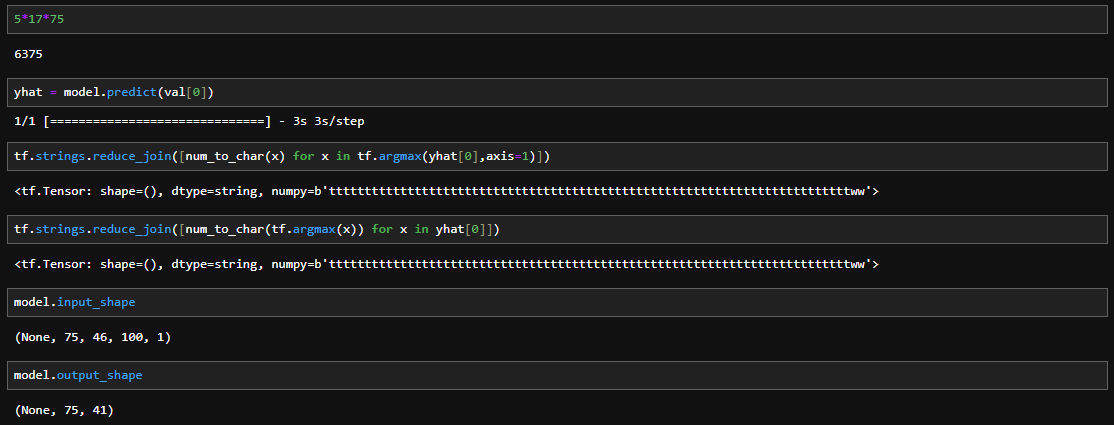
Make a Prediction